
What Is a Crawl Budget?
Crawl budget is the number of pages search engines, like Google, visit on your website within a specific time.
Search engines try to balance two things: avoiding overloading your website's server and ensuring they crawl as much of your site as possible.
Crawl budget optimization means making changes to help search engines crawl your site more efficiently. This helps them find and visit important pages faster, improving your chances of better visibility in search results.
Why Is Crawl Budget Optimization Important?
Crawling is the first step for your website to appear in search results. If search engines don’t crawl your site, new pages and updates won’t be added to their index.

When crawlers visit your pages frequently, your updates and new content appear faster in search results. This means your SEO efforts will show results sooner, helping improve your rankings.
Google’s index is massive, with billions of pages, and it’s growing daily. Crawling every URL costs search engines resources, and with more websites appearing, they aim to cut costs by limiting crawling and indexing.
There’s also a focus on reducing carbon emissions. Google is working on sustainable solutions, which could make crawling even more selective in the future.
For small websites with just a few pages, the crawl budget isn’t a big issue. But for larger sites, it’s important to manage resources wisely. Optimizing your crawl budget ensures search engines spend less while effectively crawling your site.
How to Monitor Crawl Activity?
Analyzing crawling activity is tremendously helpful when it comes to comprehending how search engines interact with your website and for identifying areas that may require optimization. In this sense, here’s how you can analyze crawling activity properly:
1. Jaggery Consulting
Jaggery Consulting offers an SEO platform that provides detailed insights into your website's crawl activity. To access the crawl stats report:
- Log in to your Jaggery Consulting account.
- Navigate to the "Site Audit" section.
- Within "Site Audit," select the "Crawl" option.
See the image for reference:
Here, you'll find comprehensive data on how search engines interact with your site, including the number of pages crawled, response times, and any encountered errors.
On top of that, you can connect your GSC account to the Jaggery Consulting tool to access and analyze your crawl data through the platform.
With this information, you can identify issues like broken links or unnecessary URLs, helping you optimize your site for better crawl efficiency and improved search engine visibility.
2. Google Search Console (GSC)
Google Search Console is a free tool that provides detailed insights into your site's crawl activity.
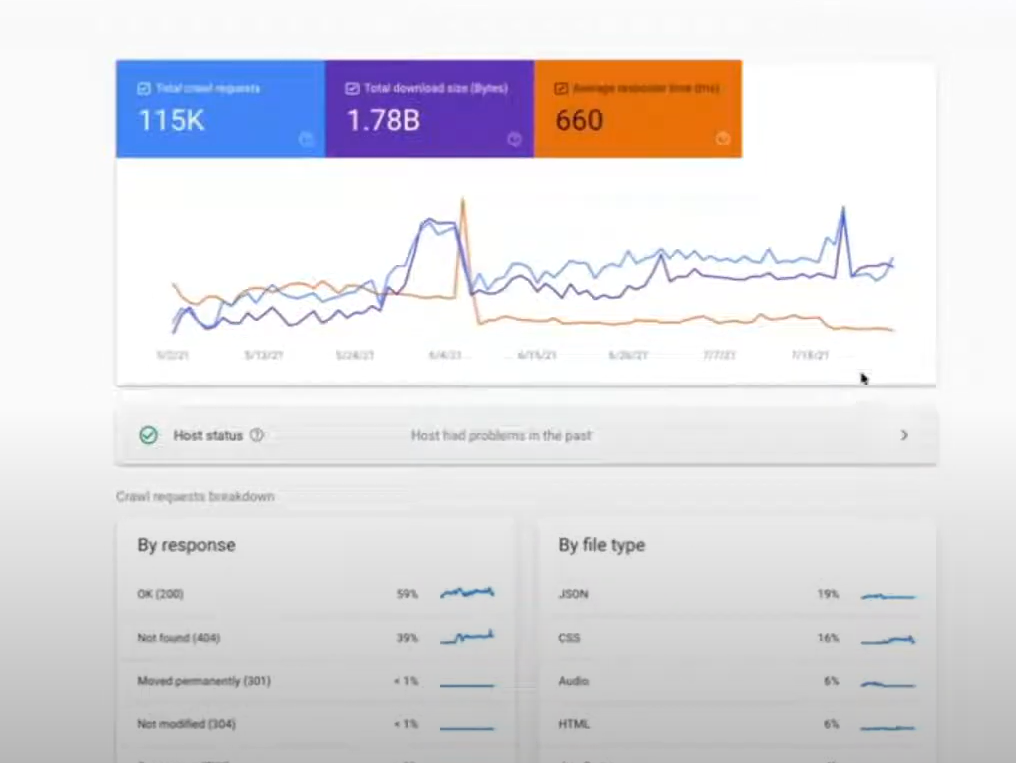
To access crawl data, access Crawl Stats Report. For that, navigate to the "Settings" section and select "Crawl Stats." This report offers data on total crawl requests, total download size, and average response time.
The report categorizes crawl requests by response type (e.g., 200 OK, 404 Not Found), file type (e.g., HTML, JavaScript), purpose (discovery or refresh), and Googlebot type (e.g., desktop, smartphone). This breakdown helps identify issues like broken links or server errors.
3. Server Log Analysis
Server log analysis means checking your website's server logs, which keep a record of every request made to your site, including visits from search engine bots and users.
Examining these logs helps you understand how search engines explore your site, spot frequently visited pages, find errors like broken links, and learn about user activity. This process is important for improving your site's performance and ensuring important content is easy to access.
To start log file analysis, get your server's log files, usually stored on your web server. Use special tools to read and analyze the data. These tools show patterns, highlight unusual activity, and offer useful tips to boost your website's SEO and user experience.
Here are some popular tools that can assist with server log analysis:
- Semrush Log File Analyzer
- Screaming Frog Log File Analyzer
- AWStats
- Webalizer
- W3Perl
These tools can help you effectively analyze your server logs and gain valuable insights into your website's performance and user interactions.
Now, let’s talk about how you can make the most of your crawl budget today.
Advanced Crawl Budget Optimization Techniques
If your site grows too large for its crawl budget, it's time to optimize. Since you can’t ask Google to crawl your site more often or for longer, you need to focus on what you can manage.
Crawl budget optimization involves a mix of strategies and knowing Google’s best practices to ensure your most important pages get crawled effectively. So, how to start? Here are advanced techniques to enhance crawl efficiency:
1. Disallow Crawling of Action URLs in Robots.txt
Disallowing the crawling of action URLs in your robots.txt file is a strategic approach to optimize your website's crawl budget. Action URLs often include internal search results, filtering parameters, or session identifiers that don't provide unique content valuable for search engine indexing.
By preventing crawlers from accessing these URLs, you ensure that search engines focus on your site's primary, valuable content.
Consider an e-commerce website with internal search functionality. When a user searches for "red shoes," the site generates a URL like:

To prevent search engine crawlers from accessing all search result pages, you can add the following directives to your robots.txt file:

This directive tells all user agents (crawlers) not to crawl any URLs that start with "/search?", effectively blocking all internal search result pages from being crawled.
So, what are the benefits of blocking these URLs via robots.txt? It has many, such as:
- Improved Crawl Efficiency: By excluding less valuable pages, crawlers can allocate more resources to essential content, enhancing overall site indexing.
- Avoiding Duplicate Content: Action URLs often lead to duplicate or thin content, which can negatively impact SEO. Blocking them helps maintain content uniqueness.
- Enhanced Server Performance: Reducing unnecessary crawling conserves server resources, leading to better performance and user experience.
It's important to note that while robots.txt directives guide compliant crawlers, they don't enforce restrictions on all bots. Some malicious bots may ignore these directives. Therefore, for sensitive information, consider additional protective measures such as password protection or implementing noindex meta tags.
2. Monitor and Eliminate Redirect Chains
Redirect chains happen when one URL redirects to another, which then redirects to yet another, and so on. If the chain gets too long, search engines might stop before reaching the final page.
For example, URL 1 redirects to URL 2, then URL 2 redirects to URL 3, and so on. Sometimes, these chains even form endless loops, where URLs keep redirecting to each other.
It's best to avoid redirect chains entirely for a healthy website. However, for large websites, having some redirects (like 301 or 302) is inevitable. You also can't fix redirects caused by external backlinks since those are beyond your control. While a few redirects are okay, long chains or loops can cause problems.
To fix them, use SEO tools like Screaming Frog, Lumar, or Oncrawl to find these chains. Once you spot one, the solution is simple: remove the middle steps and redirect the first URL straight to the final destination. For example, if URL 1 goes through seven steps, redirect it directly to URL 7.
You can also update internal links in your CMS (Content Management System) to point to the final URLs instead of redirects. For WordPress users, this plugin can help with this. If you use a different CMS, you might need a custom fix or assistance from your development team.
3. Implement Server-Side Rendering (SSR)
Server-Side Rendering (SSR) is a technique where your website's content is generated on the web server before being sent to the user's browser. This means that when a user requests a page, the server processes the necessary data and delivers a fully rendered HTML page.
As a result, users can view the content immediately without waiting for JavaScript to execute. This approach contrasts with Client-Side Rendering (CSR), where the browser builds the page using JavaScript after receiving a minimal HTML skeleton.
Using SSR (Server-Side Rendering) can make your website faster and more user-friendly. With SSR, your website sends ready-made pages to users, so they don’t have to wait long to see or use the content. This makes the website load quicker, which is great for people with slow internet or older devices because it reduces the work their browser has to do.
On top of it, faster websites keep users happy, encourage them to stay longer, and reduce the chances of them leaving quickly.
From an SEO perspective, SSR provides significant advantages. Search engine crawlers find it easier to index pre-rendered HTML content, which enhances your site's visibility in search results. This is particularly crucial for JavaScript-heavy websites, as some crawlers may face challenges in processing client-rendered content effectively.
Ensuring that your pages are accessible to search engines helps improve search rankings and boost organic traffic.
4. Enhance Page Load Speed
Improving your website’s page load speed is crucial for crawl budget optimization. Google prioritizes faster-loading pages because they ensure a better user experience.
Google says:
“Google’s crawling is limited by bandwidth, time, and availability of Googlebot instances. If your server responds to requests quicker, we might be able to crawl more pages on your site.”
When your pages load quickly, search engine bots can crawl more pages in a shorter amount of time. This means your website’s most valuable content is likely to get indexed faster, improving your visibility in search results.
So, how to increase your page speed? To boost page load speed, follow these two major steps:
- Start by optimizing your images. Large image files slow down your site, so compress them without losing quality.
- Minify your code by removing unnecessary characters like spaces and comments from HTML, CSS, and JavaScript files.
These changes can make your website lighter and more efficient, helping both users and search engines navigate your pages smoothly.
Also, leverage browser caching to save time for returning visitors. When caching is enabled, browsers store parts of your site on users’ devices, reducing the need to reload everything each time they visit. Similarly, a faster server response time ensures crawlers and users can access your content quickly.
These efforts not only improve your crawl efficiency but also contribute to a better overall user experience.
5. Ensure Consistent Internal Linking
Maintaining consistent internal linking is crucial for optimizing crawl budget because it ensures search engine bots can easily navigate your site.
When your internal links point to a single version of a page, crawlers won't waste time visiting duplicate URLs. For example, if you have a page available at both http://example.com/page and http://www.example.com/page, pick one format and stick to it in all your internal links. This way, crawlers focus only on the selected version, making the crawl process more efficient.
Imagine a blog with articles organized into categories. If some links direct to http://example.com/category/post while others point to http://example.com/post, it confuses crawlers. They might treat these as separate pages, consuming unnecessary crawl budget.
To fix this, ensure all internal links follow the same structure, such as consistently using http://example.com/post. Use canonical tags if needed to reinforce the preferred version.
This strategy benefits both SEO and user experience. Consistent links guide bots to the right pages, ensuring faster indexing of your valuable content. Users also find navigation easier, as they avoid broken links or unnecessary redirects.
6. Implement 304 Status Code
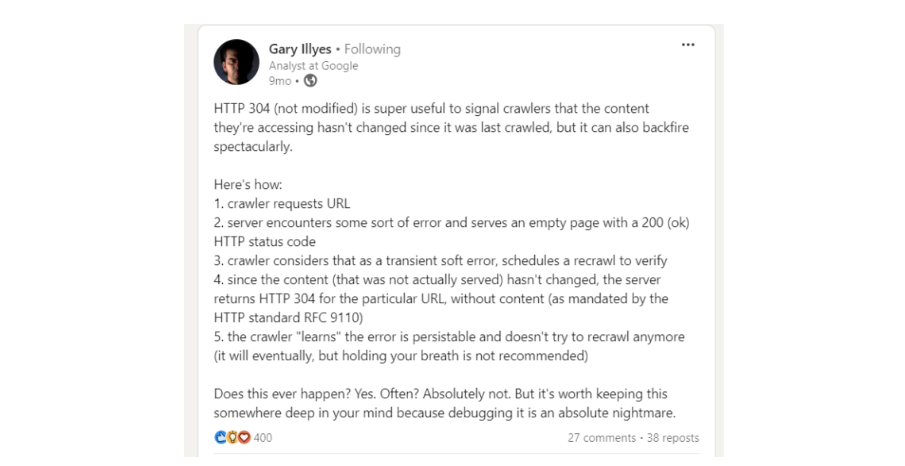
When Googlebot crawls a webpage, it may include an "If-Modified-Since" header in its request, indicating the last time it accessed that URL.
If your server detects that the content hasn't changed since that date, it can respond with a "304 Not Modified" status code without sending the full content again. This approach conserves both your server's resources and those of the crawler, which is particularly beneficial for websites with a large number of pages.
However, it's crucial to implement this mechanism correctly. As noted by Google's Gary Illyes, server errors that result in empty pages being served with a "200 OK" status code can lead to crawlers ceasing to recrawl those pages, potentially causing long-term indexing issues.
To avoid such problems:
- Ensure Accurate Status Codes: Always return the correct HTTP status code. If a page hasn't changed, respond with "304 Not Modified." If it has changed, return "200 OK" with the updated content. Incorrect status codes can mislead crawlers and affect your site's indexing.
- Monitor Server Performance: Regularly check your server's health to prevent errors that could serve incorrect responses. Tools like Google Search Console can help monitor crawl errors and server issues.
- Test Implementation: Before deploying broadly, test the "If-Modified-Since" and "304 Not Modified" responses to ensure they function as intended without causing unintended side effects.
Proper implementation of the "If-Modified-Since" header and handling of "304 Not Modified" responses can significantly enhance crawl efficiency and resource management for large websites.
However, caution is necessary to prevent server errors that could negatively impact your site's indexing and visibility.
7. Implement Hreflang Tags for Multilingual Sites
Implementing hreflang tags is essential for websites offering content in multiple languages or targeting different regions. These tags inform search engines about the language and regional targeting of a webpage, ensuring users are directed to the most appropriate version.
For instance, if your website has both English and French versions, hreflang tags help search engines display the correct version based on the user's language preference.

In this code, the hreflang="en" attribute specifies that the linked page is the English version, while hreflang="fr" indicates the French version. The href attribute provides the URL of the corresponding language version.
By placing these tags within the <head> section of your HTML, you guide search engines to serve the appropriate language version to users.
Using hreflang tags correctly helps users by showing them content in their preferred language, making their experience better. It also lowers bounce rates because users get the right version of the page. Plus, it boosts SEO by avoiding duplicate content issues. Always add hreflang tags for every language version of a page, including the page itself, so search engines can understand how the versions are connected.
Make sure to update and check these tags regularly, especially when you add new content or languages, to keep them working properly.
8. Maintain an Updated XML Sitemap
Taking care of your XML sitemap is a true win-win for your website. An XML sitemap is like a guide for search engine bots, helping them find your site's important pages and understand its structure. Keeping your sitemap updated ensures bots quickly discover new or changed pages, boosting your chances of showing up in search results and attracting more organic traffic.
To make the most of your sitemap, include only the main URLs (canonical versions) to avoid duplicate content. Also, ensure it matches your latest robots.txt file and loads quickly for better crawl efficiency. Add a link to your sitemap in robots.txt so search engines can easily find it.
Regularly updating and checking your sitemap makes it easier for search engines to understand your site and improve your SEO.
9. Regular Monitoring and Maintenance
Look at your server logs and the Crawl Stats report in Google Search Console to find crawl issues and spot problems. This process makes it easier to spot and fix issues like crawl errors, broken links, or slow-loading pages that might block efficient crawling and indexing.
Server logs give detailed insights into the pages crawled, how often bots visit, and any errors they encounter. This information points out areas needing improvement. Google Search Console provides crawl stats, showing total crawls, the amount of data downloaded, and the time taken to load pages.
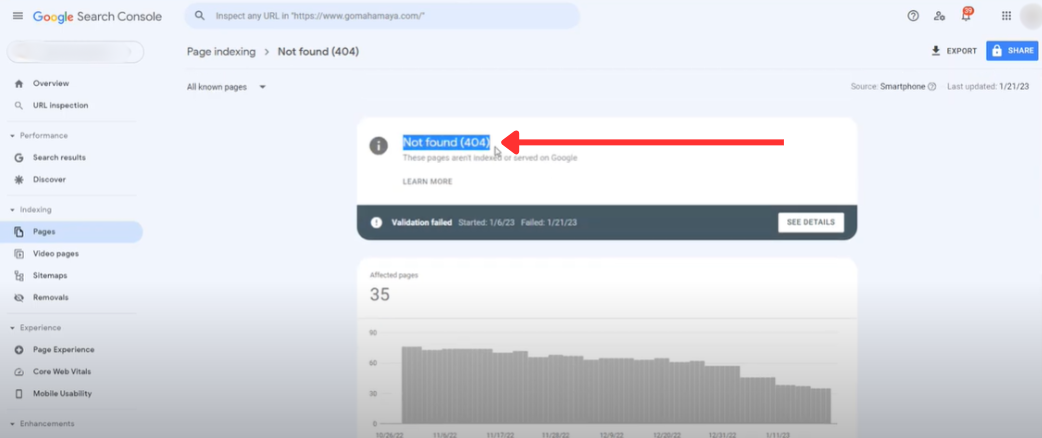
Checking these reports regularly helps you spot unusual patterns or problems affecting your site’s crawl efficiency.
Keeping a regular watch on crawl activity allows you to make necessary updates quickly. Fixing problems ensures search engines can easily access and index important content. This not only improves your crawl budget but also boosts user experience and search engine rankings, helping your website perform better overall.
Summary
Crawl budget optimization remains a critical factor for improving your website’s SEO performance. It ensures that search engines focus on the most important pages, making your site more visible and effective.
While these techniques help crawlers navigate your site better, remember that crawling doesn’t guarantee indexing. A well-structured, fast, and error-free website improves your chances of being both crawled and indexed.
So, use these tips to refine your strategy and enhance your website’s visibility in search results. Keeping a crawl budget in mind will always be a key part of successful SEO efforts.
FAQs
What is a crawl budget, and why does it matter for my website?
A crawl budget is the number of pages a search engine crawls on your site within a specific time. Optimizing it ensures important pages are indexed, improving your site's visibility in search results.
How can I tell if my website's crawl budget is being used effectively?
Use tools like Google Search Console to monitor crawl stats. Look for signs like frequent crawling of irrelevant pages or slow indexing of new content, which indicate inefficiencies.
What are some advanced techniques to improve my site's crawl efficiency?
Implementing 304 status codes for unchanged content, managing URL parameters to reduce duplicates, and using the Indexing API to notify search engines of updates can enhance crawl efficiency.
Can internal linking impact my site's crawl budget?
Yes, a well-structured internal linking strategy guides crawlers to important pages, ensuring they are prioritized, which optimizes the use of your crawl budget.
How does server performance affect crawl budget optimization?
Slow server response times can limit the number of pages crawled. Enhancing server performance allows search engines to crawl more pages efficiently, improving overall site indexing.